
AI summary
Video delivery splits into two engineering problems. Short-form feeds optimize for time-to-first-frame because viewers begin abandoning a stream once the startup passes about two seconds. Long-form catalogs optimize for sustained throughput and a low rebuffer ratio, because quality drops mid-session drive abandonment. A general-purpose web CDN handles neither well: it lacks the queue management, latency-aware routing, popularity-aware cache eviction, and origin shielding that video needs. A second requirement is security on the media path itself. Automated traffic now makes up 51% of all web requests (Imperva, 2025), and an unprotected media endpoint lets scrapers, hotlinkers, and mirror sites run on your infrastructure at your expense. A video-tuned CDN applies access control — signed URLs, geo-fencing, anomaly detection — at the edge, so delivery cost stays tied to real viewers.
A video-tuned CDN is a content delivery network built for streaming workloads, where the delivery path also enforces who is allowed to consume the stream. It differs from a general-purpose web cache in four areas: queue management, routing logic, cache eviction, and security applied on the media path. That last area is the one most teams underestimate. Automated traffic passed 51% of all web requests in 2024 (Imperva 2025 Bad Bot Report), and an open media endpoint turns your infrastructure into a free backend for scrapers and mirror sites.
Video is now the dominant traffic category — by late 2025 it accounted for roughly three-quarters of mobile traffic, a share still climbing (see why video needs a different kind of CDN). At that scale, the gap between a generic cache and a video-tuned one stops being academic. This article covers how short-form and long-form delivery diverge, why a general-purpose CDN falls short for video, and how edge-level access control became part of the delivery architecture.
How short-form and long-form delivery diverge
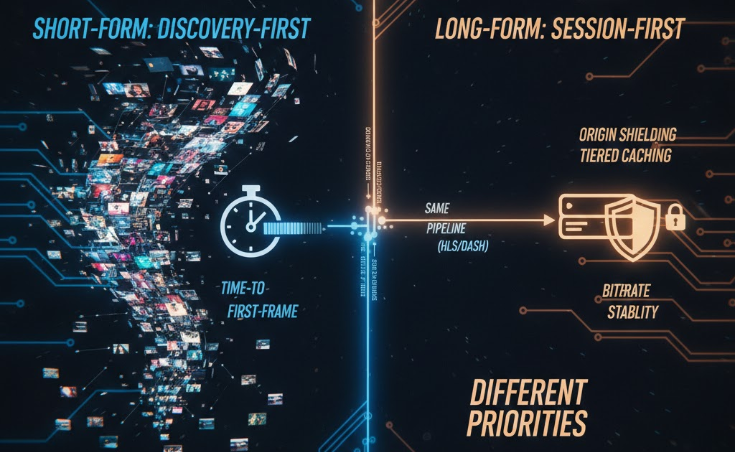
Short-form and long-form platforms rely on the same baseline: HLS or DASH manifests, segmented media storage, an origin shield, and edge cache nodes placed close to the viewer. HLS is specified in IETF RFC 8216; DASH in ISO/IEC 23009-1. The divergence happens after the request arrives, and it comes entirely from viewer behavior. The same pipeline ends up optimizing for two different bottlenecks.
How does discovery-first behavior change edge caching for short-form content?
Short-form viewers switch clips constantly and expect the next one to play the instant they scroll. To hit that, players prefetch the opening segments of upcoming clips before the viewer reaches them. A feed scrolling at speed can have three to five clips buffering ahead of the one on screen.
The cost shows up as wasted bandwidth, since a meaningful share of prefetched segments belong to clips the viewer never opens. The startup metric is unforgiving here. Akamai’s analysis of 23 million streaming sessions found that abandonment climbs once startup passes two seconds, with every additional second of delay adding 5.8% to the abandonment rate (Krishnan and Sitaraman, Video Stream Quality Impacts Viewer Behavior). For a scrolling feed, that two-second budget is the entire product.
How does session-first viewing change priorities for long-form catalogs?
Long-form viewers behave the opposite way. They tolerate a brief startup buffer, then commit to a session that can run for hours. What they will not tolerate is quality dropping or the stream freezing partway through a title.
That shifts the optimization target from startup speed to sustained throughput and rebuffer prevention. Industry telemetry from Conviva and Mux puts the practical ceiling around a 1% buffer ratio for a clean experience; once rebuffering passes roughly 5% of playback time, abandonment rises sharply. Long-form systems lean on deep tiered caching and origin shielding to keep that ratio low when concurrency spikes. Platforms scaling a large catalog hit this directly — see how delivery changes scaling video from 100 TB to petabyte levels.
The three differences that matter operationally:
| Dimension | Short-form | Long-form |
| Primary metric | Time-to-first-frame | Rebuffer ratio, bitrate stability |
| Traffic pattern | Rapid bursts of concurrent starts and switches | Steady, long-duration sessions |
| Cache behavior | Localized edge hits, speculative prefetch | Efficiency across a deep library |
Why a general-purpose CDN falls short for video
A general-purpose CDN is built to cache and serve discrete files — images, scripts, HTML. Video is a stream of small, time-ordered segments fetched in sequence under a latency constraint, often by many viewers at once. A generic cache lacks the queue management and routing logic to deliver concurrent video chunks without inducing jitter or packet loss.
Here is where the two diverge in practice:
| Parameter | General-purpose web CDN | Video-tuned CDN |
| Cache unit | Whole files, page assets | HLS/DASH segments and manifests |
| Routing logic | Geographic proximity | Lowest measured latency, RTT-aware |
| Cache eviction | LRU, cache-on-first-request | Popularity-aware, protects hot content |
| Origin protection | Basic | Origin shield plus tiered cache hierarchy |
| Connection profile | Short-lived requests | Sustained, many concurrent segment fetches |
| Media-path security | Limited | Token validation, geo-fencing, anomaly detection at the edge |
| Key rotation | Not applicable | Dual-secret signed URL support |
Does a video-tuned CDN improve startup and seek times?
It does, by routing on measured latency instead of raw geographic distance. A node that is physically closer is not always faster, because peering quality, congestion, and path length all interfere. Latency-aware routing picks the path with the lowest round-trip time, so when a viewer seeks a new timestamp, the edge responds without waiting for a fresh handshake to a distant origin.
Can a video CDN shield origin servers from mass concurrent spikes?
Yes. Origin shielding and tiered cache hierarchies stop a mid-tier cache miss from turning into a stampede against central storage. When a popular title draws a large simultaneous audience, the CDN collapses identical requests at the regional layer — a thousand viewers asking for the same segment become one origin fetch. Origin load stays flat while the audience grows.
Does smarter cache eviction control infrastructure cost?
It does, for deep catalogs. Naive cache-on-first-request logic lets a cold, rarely watched file evict a hot one simply because it was requested more recently. Popularity-aware eviction keeps high-demand content resident and pushes long-tail assets to lower tiers. The result is fewer origin fetches and lower egress, which is the line item that scales fastest on a large library.
The delivery path as a security control plane
Streaming endpoints at scale serve not only human viewers. A public media endpoint is scanned, scraped, and hotlinked the moment it exists. Imperva blocked 13 trillion bad bot requests across its network in 2024, with bad bots accounting for 37% of all internet traffic. If your delivery network cannot judge request legitimacy in real time, it serves automated clients as readily as real ones, and pays the bandwidth bill for both.
Why is access control now part of the delivery architecture?
Because the alternative — checking access at the application layer, after the request has already reached your origin — adds latency for legitimate viewers and still lets abuse through. Putting enforcement on the media path itself keeps playback clean for real users while making automated reuse expensive or impossible. The hard part is not blocking obvious attacks. It is telling automated reuse apart from human consumption when both use a normal browser, fetch valid manifests, and request valid segments.
The economics of hotlinking
Hotlinking is the cleanest example of how an open media path leaks money.
A hotlinker embeds your media URLs directly into their own pages using standard HTML5 <video> or <iframe> tags. Their site shows your video, their site sells the ad impression, and your infrastructure absorbs the delivery cost and the hardware strain. The economics are entirely backwards: you pay to serve an audience that someone else monetizes.
It is hard to filter with basic rules because the requests look legitimate at the network layer. They come from real browsers fetching real files. Referer and Origin headers are trivially spoofed, and residential IP addresses overlap with your genuine audience — Imperva found 21% of bot attacks now route through residential proxies specifically to blend in. Simple referer blocklists produce false positives against real viewers and still miss a competent hotlinker.
Layered controls on the media path
No single mechanism stops unauthorized streams. A defensible setup runs several independent controls, each closing a different gap, so that defeating one does not open the door. Advanced Hosting applies this layered model in its Video CDN so that genuine viewing stays unaffected while redistribution paths break:
Signed URLs. Each segment and manifest request carries a cryptographic signature, typically an HMAC-SHA256 token, plus an expiry timestamp (TTL). A harvested link stops working once the TTL passes — commonly 60 to 300 seconds — so a scraped URL is dead before it can be redistributed. Binding the token to the requesting IP raises the cost further, since the link only works from the address it was issued to.
Referer and Origin validation. The edge checks request headers against an allowlist of approved domains. This stops casual iframe embedding. It is the weakest layer on its own, since headers spoof easily, which is exactly why it sits underneath signed URLs rather than replacing them.
Geo-IP enforcement. Licensing and compliance boundaries are enforced at the edge node, before a segment is served, rather than inside the application.
Transport hardening. HTTPS-only delivery closes common browser-side leakage paths. Native apps can add certificate pinning to make man-in-the-middle token capture harder.
Anomaly detection. Edge nodes score request patterns against what real playback looks like. A client that loads every segment of a title back-to-back at machine speed, never pauses, never seeks, and never abandons is not a person. Probabilistic scoring flags that sequence even when each individual request is valid.
Do edge controls need to adapt to harvesting bots?
They do. A competent scraper runs a headless browser, executes JavaScript, and harvests valid media tokens before redistributing them. Static rules cannot catch that. Edge nodes have to evaluate request sequences probabilistically and decide whether the pattern reflects human playback or automated collection.
Is an edge firewall enough on its own?
No. Edge enforcement has to sync with application-layer monitoring. An attacker harvesting links through your genuine storefront looks fine to the edge, since the requests are signed and valid. What gives them away is the rate of session or token creation at the application and database layer. Watching that rate is what stops industrial-scale harvesting that passes every edge check individually.
Rotating keys and handling crawlers without breaking playback
Signing keys can be rotated without interrupting live viewers if the delivery framework supports two concurrent shared secrets. During a key rollover, the edge validates incoming signed URLs against both the primary and the secondary secret. Tokens issued under the old key keep working until they expire naturally; new tokens use the new key. Once the old tokens age out, the retired key is dropped. Active viewers see nothing.
Without dual-secret support, a key rotation invalidates every token in flight at once, and every viewer with an active stream hits a playback error simultaneously. That is a self-inflicted outage, and it is avoidable.
Will aggressive anti-scraping rules block search engines from indexing my pages?
They can, if they are careless. Strict bot rules that match on User-Agent strings will eventually block a legitimate crawler and quietly drop your search visibility, which is a real cost for any platform that depends on discovery.
The fix is to verify crawler identity properly. User-Agent strings are spoofable, so a Googlebot UA proves nothing. Confirm the request against Google’s published IP ranges, or run a reverse DNS lookup followed by a forward lookup to confirm the result resolves back to the same address. Verified crawlers bypass the anti-scraping layer; spoofed ones do not.

Can a distributed CDN absorb a DDoS attack on its own?
Partly. A global CDN naturally dilutes a volumetric flood by spreading incoming traffic across thousands of edge processors, so a network-layer attack that would flatten a single origin gets absorbed by surface area. Application-layer attacks are different. They mimic real requests and need on-demand mitigation profiles that filter the attack without adding latency to legitimate streams. Distribution helps with volume; it does not replace targeted mitigation.
Where the financial risk concentrates
All streaming platforms don’t need the same level of perimeter security. Every public endpoint is scanned, but the financial consequences of a breach depend on the catalog structure, monetization model, and demand for the content. For some categories, unauthorized access shifts from a routine infrastructure expense into a primary driver of revenue loss.
UGC and tube-style catalogs
A large user-generated catalog is a standing target for aggregators that scrape, download, and re-upload content to competing sites. The damage is not only the stolen content. Persistent scraping breaks the assumptions a cache is tuned around.
Scrapers crawl the cold long tail of a library rather than the hot, cached segments real viewers request, so the cache hit ratio drops. Those uncached requests force the origin storage layer into intensive disk I/O for low-value traffic. Egress costs creep up quietly, because harvesting reads like steady background noise rather than an obvious spike. And when a genuine viral spike does arrive, the capacity that background harvesting has been consuming is no longer there as headroom. For platforms in this position, video streaming infrastructure has to be sized for the automation tax, not just the audience.
Subscription and premium content
When a stream carries an explicit price — pay-per-view, a subscription tier, a creator paywall — every leaked link is lost revenue. Harvesting networks systematically collect active stream URLs and resell access through unauthorized portals.
The revenue loss maps one-to-one: an unauthorized viewer is a viewer who bypassed the conversion funnel entirely. Credential and link sharing also raises support costs, triggering concurrent-stream lockouts that annoy paying subscribers. High-value titles draw piracy networks that monitor players to capture fresh segments. Left unaddressed, a top-tier asset becomes a liability whose delivery cost is decoupled from the revenue it earns. This is the core constraint behind VOD and OTT infrastructure, where the catalog itself is the business.
Interactive streaming platforms
High-traffic media platforms, including interactive streaming, run under some of the most aggressive redistribution pressure on the internet: constant hotlinking, very deep long-tail libraries, fast preview behavior, and organized mirroring.
External embedding and site mirroring are continuous, so scraping pressure against the origin never lets up. Fast user navigation makes harvesting hard to isolate, because real viewers also generate quick bursts of segment requests. Bandwidth bills rise independently of on-site ad revenue, so operations absorb traffic cost while monetization stays flat. And takedowns create churn: mirror sites rotate endpoints quickly to keep harvesting freshly uploaded content. Platforms in this segment need infrastructure built for interactive streaming, where edge enforcement is a default, not an add-on.
Enterprise and educational streaming
Corporate and institutional platforms rarely face industrial piracy, but they have a strict requirement of their own: content has to stay inside a defined audience. If an internal video leaks past the corporate boundary, the platform has failed its core job.
Access has to be bounded and verifiable, because the platform’s value comes entirely from keeping content private. Compliance parameters are a baseline requirement rather than an add-on. Corporate networks are messy, so validation has to be flexible enough that employees behind NATs or VPNs can stream reliably without punching a hole in the policy. And every edge transaction usually has to be logged and attributable for audit.
How Advanced Hosting’s Video CDN handles this
Advanced Hosting runs a Video CDN built specifically for streaming workloads, with edge enforcement applied on the media path rather than after the fact. It is a separate product from the company’s anycast CDN, which is tuned for small static files.
The delivery side covers latency-aware routing, origin shielding, tiered caching, and popularity-aware eviction — the calibrations that keep startup low and rebuffering rare under concurrent load, across the company’s global edge network. [AH NOC: insert a real metric here — for example median time-to-first-frame, edge cache hit ratio, or origin-offload percentage across the network.]
The security side runs the layered model described above: signed URLs with configurable TTLs, IP-bound tokens, dual-secret key rotation for zero-interruption rollovers, geo-IP enforcement, verified-crawler bypass, and edge anomaly detection synced with application-layer rate monitoring. [AH NOC: insert a real figure — for example scraper or hotlink traffic filtered as a share of requests, or DDoS mitigation capacity in Tbps.]
For a platform weighing this against a general-purpose CDN, the practical question is whether infrastructure cost stays tethered to real human viewers or floats free of it.
Summing Up
Video delivery and video security stopped being separate problems. Poor delivery tuning makes a platform easier to abuse, and unmitigated automation distorts the metrics you scale against. A production-grade video CDN has to do both jobs at once: hold throughput steady under concurrent load, and validate access on the media path so external sites cannot run on your hardware. Done right, infrastructure cost stays tied to real viewers and predictable growth.
If you want to know where your platform sits on this curve, talk to a CDN engineer. We will review your current delivery flow and traffic patterns and propose a Video CDN setup that improves playback, stabilizes peak performance, and reduces the hidden bandwidth tax caused by abuse.
What is a video-tuned CDN and how is it different from a regular CDN?
A video-tuned CDN is optimized for streaming workloads — HLS/DASH segment delivery, latency-aware routing, origin shielding, and security enforcement on the media path. A general-purpose CDN caches discrete files and routes on geographic proximity, which leaves it short on queue management and concurrency handling for video. Definitions for the terms used here are in the Advanced Hosting glossary.
Does hotlinking actually cost money?
Yes, directly. A hotlinker embeds your media URLs in their own pages and serves your video to their audience. They collect the ad revenue; you pay the bandwidth and hardware cost. On a high-traffic platform this becomes a significant, and often invisible, line item.
How do signed URLs stop link sharing?
Each media URL carries an HMAC signature and an expiry timestamp. Once the TTL passes — often 60 to 300 seconds — the link stops working. Binding the token to the requesting IP address narrows it further, so a shared or harvested link fails before it can spread.
Can I rotate signing keys without interrupting live viewers?
Yes, if your delivery framework validates against two shared secrets at once. Old tokens stay valid until they expire; new tokens use the new key. Without dual-secret support, a rotation breaks every active stream simultaneously.
Will anti-scraping rules block Google from indexing my video pages?
They can, if the rules match on User-Agent strings, which are easy to spoof. Verify crawler identity against published IP ranges, or with reverse-plus-forward DNS lookups, and let verified crawlers bypass the anti-scraping layer.
How much of my streaming traffic is likely automated?
Across the internet, automated traffic passed 51% of all web requests in 2024, with bad bots at 37% (Imperva 2025 Bad Bot Report). The share hitting a specific media endpoint depends on catalog value and exposure; on a popular open catalog it can be substantial.
Do short-form and long-form platforms need different CDN configurations?
They share the same baseline stack but tune it differently. Short-form prioritizes time-to-first-frame and speculative prefetch; long-form prioritizes sustained throughput, deep caching, and a low rebuffer ratio.
Is a CDN enough to stop a DDoS attack?
A distributed CDN absorbs volumetric, network-layer floods well by spreading traffic across many edge nodes. Application-layer attacks need on-demand mitigation profiles on top, because they imitate real requests and distribution alone does not filter them.
What edge controls matter most for paywalled or regulated content?
Signed URLs with short TTLs and IP binding, geo-IP enforcement for licensing boundaries, and concurrent-stream limits tracked at the application layer. Regulated verticals such as iGaming infrastructure add audit logging of every edge transaction.





