
AI summary
This article addresses how to design and operate production-grade private clouds using OpenStack. It emphasizes that a reliable deployment requires coordinated engineering across networking, distributed storage, automation, high availability, capacity planning, and operational processes so that compute, networking and storage are presented as programmable, multi-tenant resources.
Bottom line: building a private cloud is an infrastructure engineering effort rather than a simple software install. Success depends on standardizing hardware and configurations, isolating traffic types, adopting shared distributed storage and repeatable automated deployment and lifecycle practices, and designing for resilience and gradual scaling; organizations can also mitigate risk by engaging specialist managed services when internal expertise or time is limited.
Building a private cloud with OpenStack is far more than installing virtualization software. A production-ready environment requires carefully designed networking, distributed storage, automation, high availability, and scalable infrastructure architecture. In this technical guide, we explain how OpenStack works, how to deploy it properly, and how to avoid the operational mistakes that commonly break private cloud environments. You’ll learn about Kolla-Ansible, Ceph integration, Neutron networking, HA architecture, cluster sizing, and performance optimization, along with practical engineering recommendations and infrastructure insights from Advanced Hosting experts.
How to Build a Private Cloud Using OpenStack
Private cloud adoption is accelerating rapidly as companies seek greater infrastructure control, predictable cost structures, and rigorous workload isolation. OpenStack remains the industry-standard platform for building enterprise-grade private cloud environments because it integrates compute virtualization, software-defined networking (SDN), distributed storage, and multi-tenant orchestration into a single open-source ecosystem.
Advanced Hosting Tip: Many companies underestimate the operational advantages of infrastructure ownership. Predictable workloads often become dramatically more cost-efficient in dedicated private cloud environments compared to hyperscale public cloud billing models.
This guide details the end-to-end framework required to architect, deploy, scale, and maintain a production-ready OpenStack cloud environment.
1. Why Enterprises Choose OpenStack
Organizations use OpenStack to achieve the programmatic flexibility of a public cloud without the unpredictable data egress billing and compliance risks of third-party hyperscalers.
Primary Production Use Cases
- High-Density Virtualization: Consolidating legacy bare-metal servers into dynamic, multi-tenant virtual environments.
- AI & Machine Learning Pipelines: Orchestrating bare-metal GPU clusters and pass-through virtual accelerators.
- Telecom & Edge Architectures: Powering Network Functions Virtualization (NFV) and low-latency edge nodes via distributed compute topologies.
- Cloud-Native Development Clouds: Providing internal engineering teams with on-demand Kubernetes provisioning via OpenStack Magnum or APIs.
Enterprise Economics Tip: While public clouds are ideal for highly elastic, variable workloads, predictable baseline workloads are often 30%–50% more cost-efficient when run on dedicated OpenStack private infrastructure over a 3-year lifecycle.
2. Core OpenStack Architecture Explained
OpenStack is not a monolithic application; it is a highly distributed control plane composed of modular services that communicate asynchronously via REST APIs and an AMQP message broker (usually RabbitMQ).
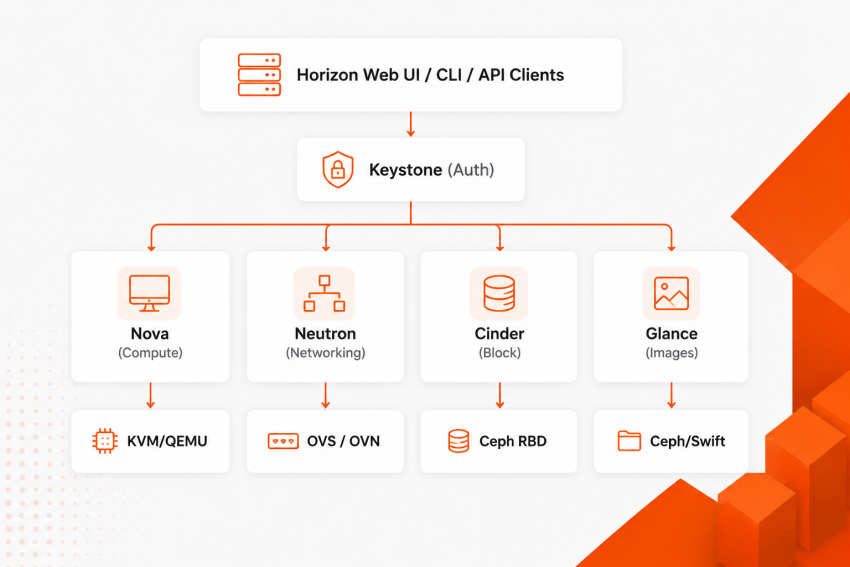
What Is OpenStack and How Does It Work?
OpenStack is an open-source Infrastructure-as-a-Service platform that manages compute, networking, storage, and cloud orchestration.
An effective way to approach OpenStack architecture explained is to think of it as a distributed control system that manages physical infrastructure as programmable cloud resources.
Core OpenStack services include:
| Component | Service Name | Core Technical Purpose |
| Identity | Keystone | Centralized authentication, token generation, and multi-tenant RBAC. |
| Compute | Nova | Manages hypervisors, provisions instances, and schedules workloads. |
| Networking | Neutron | Orchestrates virtual switches, routers, firewalls, and floating IPs. |
| Block Storage | Cinder | Attaches persistent block volumes to instances via iSCSI or Ceph RBD. |
| Image Storage | Glance | Discovery, registration, and delivery services for VM disk images. |
| Placement | Placement | Tracks resource inventory (CPU, RAM, disk) to optimize scheduling decisions. |
| Orchestration | Heat | Declarative, template-driven infrastructure automation (similar to Terraform). |
| Dashboard | Horizon | Extensible web-based user interface for administrators and tenants. |
Advanced Hosting Tip: Standardizing server configurations dramatically reduces troubleshooting complexity during scaling and maintenance operations.
3. Hardware Sizing & Minimal Architecture
Designing physical hardware infrastructure demands consistency. Heterogeneous server builds create scheduling imbalances, complicate live migrations, and drastically increase troubleshooting overhead.
Recommended Production Blueprint
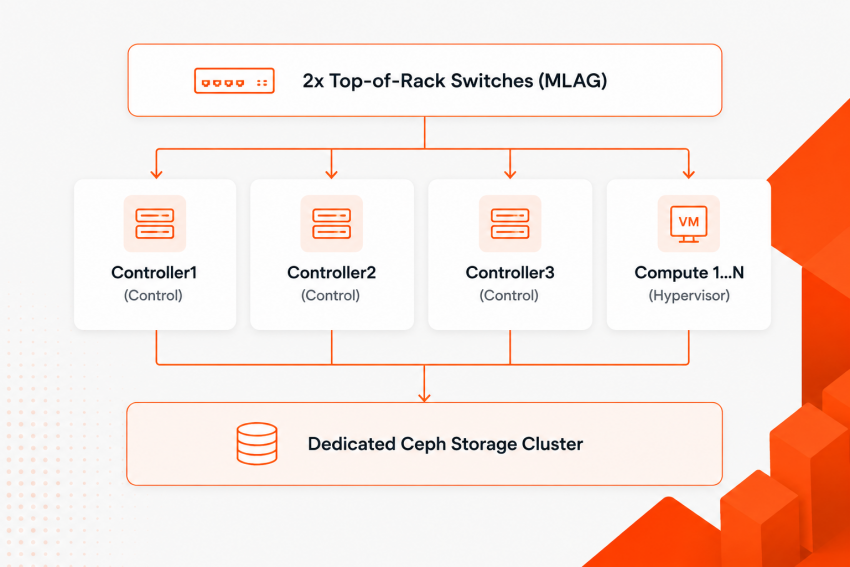
Control Plane (Minimum 3 Nodes for High Availability)
- CPU: 2× Intel Xeon / AMD EPYC (16+ cores per socket)
- RAM: 128 GB minimum (to comfortably host Galera, RabbitMQ, and API containers)
- Disk: 2× 480 GB NVMe (RAID-1 for OS and logs)
- NICs: 2× 10/25 GbE ports bonded
Compute Nodes (Scale Horizontally)
- CPU: High core-count processors matched across all nodes (enables seamless live migration)
- RAM: 256 GB to 1 TB+, depending on desired virtual machine density
- Disk: Small local SSD/NVMe array for OS and ephemeral cache (if not using boot-from-volume)
- NICs: 2× 25 GbE ports bonded
Storage Tier (Minimum 3 Nodes for Ceph Object Storage Daemons)
- CPU: Single or dual-socket multi-core CPU
- RAM: Minimum 4 GB of RAM per Terabyte of OSD capacity
- Disk: Enterprise-grade NVMe or SAS SSDs (No spinning platters for primary IOPS pools)
- NICs: 2× 25/100 GbE ports bonded (storage replication generates heavy East-West traffic)
4. Engineering the Network Layer
Networking misconfigurations are the leading cause of failed OpenStack implementations. To build a highly available cloud, you must separate distinct traffic types onto dedicated physical links or isolated 802.1Q VLANs.
Traffic Isolation Map
- Management Network: Internal control plane communication, API calls, DB replication, and RabbitMQ traffic. Private routing only.
- Storage Network (Frontend): Maps VM instances to Cinder/Glance storage backends.
- Storage Clustering Network (Backend): Used exclusively by Ceph for data replication, scrubbing, and rebalancing.
- Overlay Network (Tenant Traffic): Carries encapsulated tunnel traffic (VXLAN/GENEVE) between compute nodes.
- External Network: Public or corporate routing pool for assigning Floating IPs to customer instances.

Modern SDN Architecture: Open Virtual Network (OVN)
While legacy deployments rely on Open vSwitch (OVS) with centralized Neutron agents, modern clouds should use OVN. OVN introduces a native distributed routing architecture:
- Distributed Virtual Routing (DVR): Routing between tenant subnets (East-West traffic) happens directly on the compute node, eliminating the performance bottleneck of hair-pinning traffic through a centralized controller network node.
- Native Security Groups: Leverages OVS flow tables directly, removing the performance penalty of legacy Linux iptables bridges.
5. Storage Design: The Ceph Advantage
Running a production OpenStack cluster using local compute storage creates operational risk and eliminates high-availability capabilities like automatic evacuation and live migrations.
Integrating Ceph as a unified distributed storage fabric is the industry gold standard:
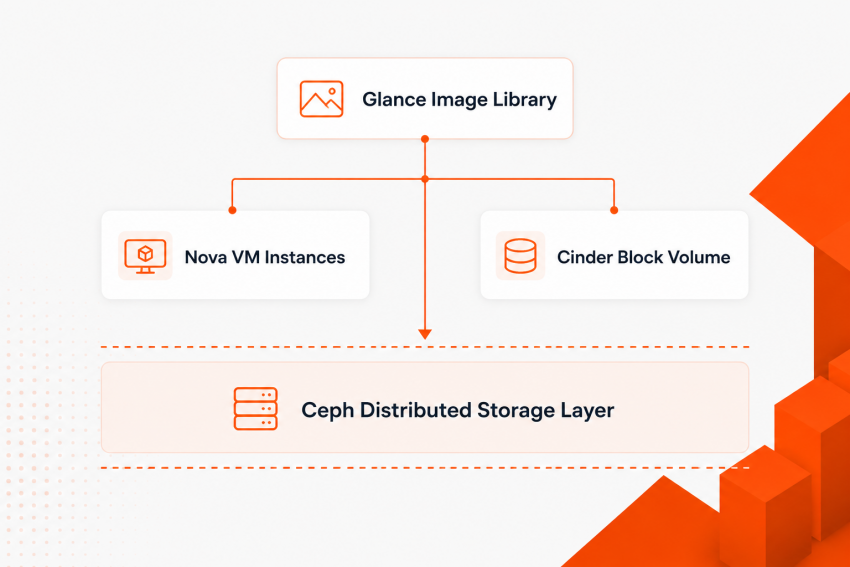
Key Integrations
- Cinder & Glance Cohesion: When a tenant boots a VM from an image, Ceph performs an instantaneous copy-on-write clone. Rather than copying a 20 GB RAW file across the network, the VM boots in seconds.
- Live Migration: Because instance disks reside on a shared Ceph cluster (RBD), virtual machines can live-migrate between physical hosts in real-time with zero packet loss or disk sync delays.
- Fault Isolation: If a compute node suffers a catastrophic hardware failure, OpenStack’s control plane detects the loss and automatically recreates the instances on an alternate node, instantly remapping the remote persistent Ceph volume.
6. Efficient Deployment Frameworks
Never attempt to install a production OpenStack cluster manually (“OpenStack The Hard Way”). The platform contains hundreds of individual configuration parameters that must remain uniform across your infrastructure.
The Standard: Containerized Deployment via Kolla-Ansible
The most reliable way to install, manage, and upgrade an enterprise cluster is Kolla-Ansible. This framework packages every OpenStack service into isolated, highly optimized Docker/Podman containers and uses Ansible to automate the configuration and lifecycle across nodes.
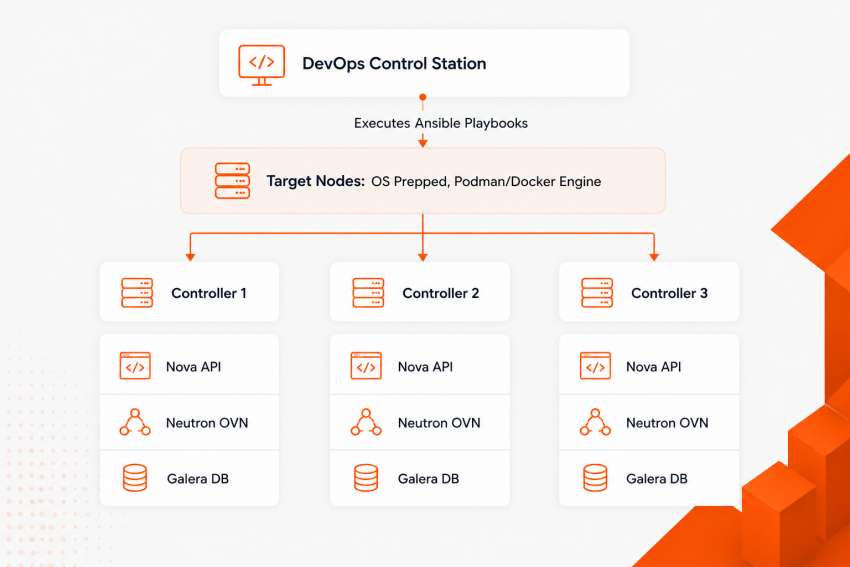
High-Level Kolla-Ansible Deployment Pipeline
- Node Provisioning: Deploy a clean base operating system (Ubuntu Server or RHEL) on all targets using PXE/Ironic.
- Define Inventory: Configure /etc/kolla/globals.yml to specify your VIPs, network interface maps, storage backends (Ceph external), and target service parameters.
- Bootstrap Servers: Execute the bootstrap command to install container engines and system dependencies:

4. Execute Service Orchestration: Pull containers, inject configurations, initialize databases, and start the control plane:

Should You Use Managed OpenStack Deployment Services?
Managed services significantly reduce operational risk.
Many organizations choose OpenStack deployment services because building internal expertise requires substantial time and operational investment.
Managed providers help with:
- architecture design
- deployment automation
- lifecycle management
- monitoring
- upgrades
- security hardening
- scaling operations
This approach allows internal teams to focus on applications rather than infrastructure maintenance.
Advanced Hosting Tip: The most successful private cloud projects treat infrastructure as a continuously evolving platform rather than a one-time deployment.
Building a private cloud with OpenStack is not simply a software installation project. It is an infrastructure engineering initiative that combines networking, storage, virtualization, automation, and operational maturity into a unified platform.
Organizations that approach OpenStack strategically, starting with a small, highly reliable foundation and scaling gradually, often gain substantial advantages in:
- infrastructure control
- workload flexibility
- predictable operating costs
- performance consistency
- long-term scalability
The key is designing for operational simplicity, automation, and resilience from the very beginning.
What Is OpenStack Neutron Networking?
Neutron provides virtual networking services for OpenStack workloads.
OpenStack Neutron networking allows administrators to create:
- virtual routers
- software-defined switches
- floating IPs
- security groups
- tenant isolation
- load balancing
- virtual subnets
Neutron effectively transforms physical networking into programmable infrastructure.
Most enterprise deployments use:
- Open vSwitch (OVS)
- OVN (Open Virtual Network)
- VXLAN overlays
- distributed virtual routing
Neutron also enables:
- multi-tenant isolation
- network automation
- API-driven provisioning
- scalable segmentation.
How Do You Deploy OpenStack Efficiently?
Use automated deployment frameworks instead of manual installation.
Understanding how to deploy OpenStack properly means embracing infrastructure automation from the beginning.
Manual deployments quickly become unmanageable because OpenStack contains dozens of interconnected services. Automated deployment frameworks standardize installation, upgrades, and operational consistency.
The most widely adopted approach today is:
- containerized services
- Ansible-based automation
- declarative configuration management
This significantly improves:
- repeatability
- upgrade safety
- operational recovery
- infrastructure consistency
Why Is Kolla-Ansible Popular?
It simplifies OpenStack deployment using containers and automation.
A modern Kolla-Ansible deployment packages OpenStack services into Docker containers managed through Ansible playbooks.
Benefits include:
- simplified upgrades
- isolated services
- reproducible deployments
- easier rollback procedures
- cleaner dependency management
Kolla-Ansible is especially useful for:
- proof-of-concept environments
- production deployments
- hyper-converged infrastructure
- edge cloud platforms
The deployment workflow usually includes:
- OS preparation
- inventory configuration
- network definition
- container registry setup
- service deployment
- post-deployment validation
How Should Storage Be Designed?
Distributed storage is essential for resilient private cloud infrastructure.
Reliable private cloud infrastructure depends heavily on storage architecture because storage failures affect every workload running inside the cloud.
Most production environments combine:
- local NVMe storage
- distributed replication
- object storage
- block storage
- high-throughput networking
Ceph has become the dominant storage platform for OpenStack because it integrates tightly with:
- Cinder
- Glance
- Nova
- object storage workflows
Why Is OpenStack Ceph Integration Important?
Ceph provides scalable, fault-tolerant distributed storage for OpenStack.
Successful OpenStack Ceph integration allows virtual machines, images, and persistent volumes to operate on distributed replicated storage instead of local disks.
Advantages include:
- high availability
- storage replication
- self-healing behavior
- horizontal scaling
- flexible performance tiers
Ceph clusters typically separate:
- monitor nodes
- OSD storage nodes
- metadata services
- client access networks
This architecture improves resilience while reducing single points of failure.
What Makes an OpenStack Environment Highly Available?
Redundancy must exist at every infrastructure layer.
A resilient OpenStack HA architecture includes redundancy for:
- controllers
- networking
- storage
- power
- APIs
- message queues
- databases
Typical HA components include:
- MariaDB Galera Cluster
- RabbitMQ clustering
- HAProxy
- Keepalived
- Ceph replication
High availability is not just about uptime. It also improves:
- maintenance flexibility
- upgrade safety
- workload mobility
- operational resilience
How Do You Handle OpenStack Production Deployment?
Production environments require operational discipline beyond installation.
An OpenStack production deployment is fundamentally different from a lab environment. The focus shifts toward:
- monitoring
- observability
- automation
- backup strategy
- lifecycle management
- security hardening
- upgrade planning
Production teams typically implement:
- Prometheus monitoring
- centralized logging
- automated alerting
- infrastructure-as-code
- disaster recovery workflows
Capacity planning also becomes continuous rather than static.



")

